Mizar's management plane is based on Kubernetes based operators. The management-plane a fully distributed, elasticaly scaling, and kubernetes-native design. Several existing components allows this design to happen, which we reuse:
- Kubernetes Custom Resouce Definition: Allows us to extend the K8s API server with networking objects. Some of these objects are generic to any networking solutions and some of them are specific to Mizar.
- Kubernetes Operator Framework: Operators Pattern helps extending Kubernetes with domain-specific operators that client APIs that act as a controller for CRDs. Operator frameworks allow us to write custom lightweight operators the derive the networking objects life-cycle. We particulary use Kopf extensively as it allows us to easily refactor the test controlle.
- LMDB: Provides a light-weight in-memory transactional database that is local to each Operator.
- Luigi: Facilitates deveopling, scheduling and executing workflows.
Object-Pipeline Architecture
The following diagram illustrates the overall architecture of the management plane. The main components of this architectures are objects and operators.
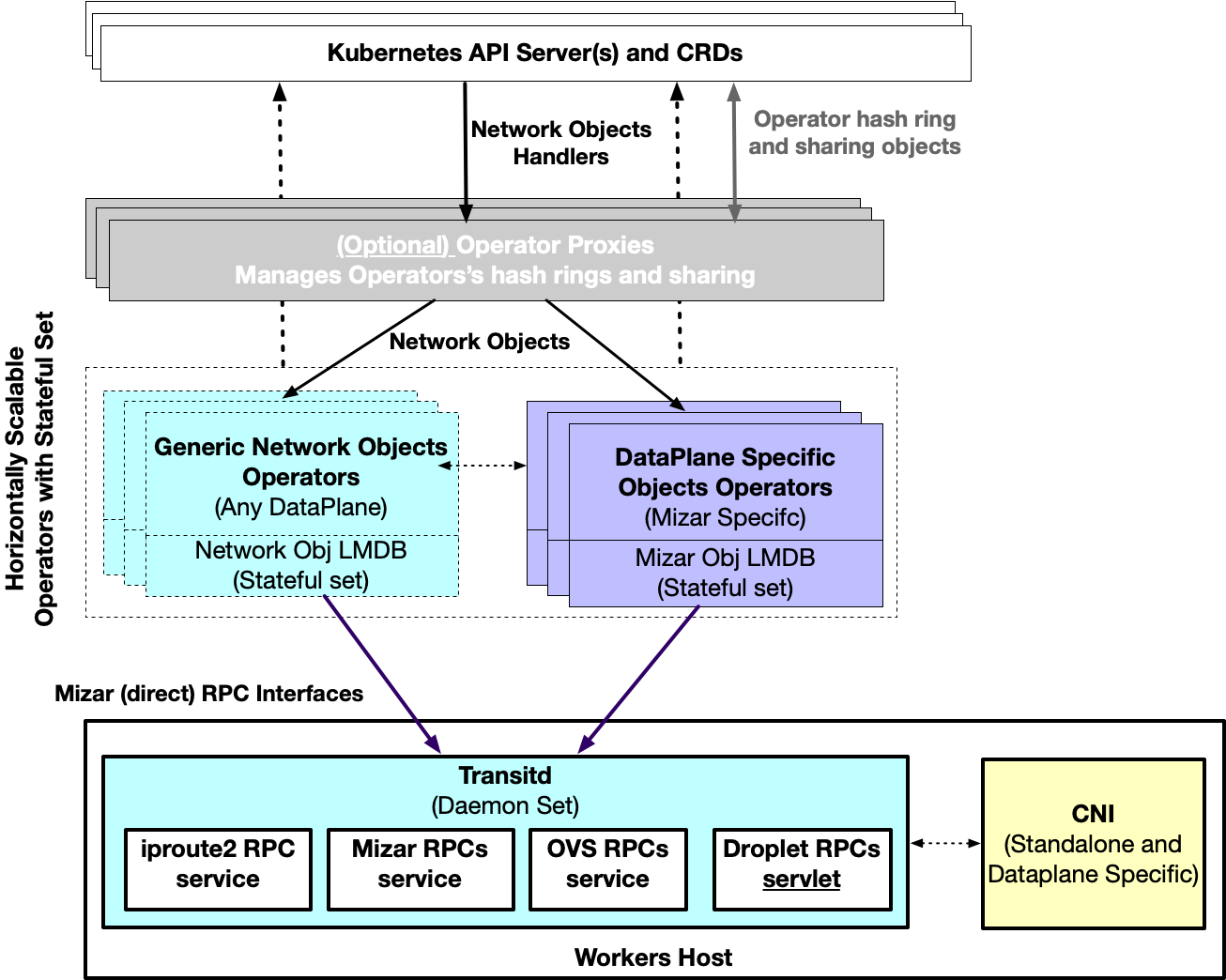
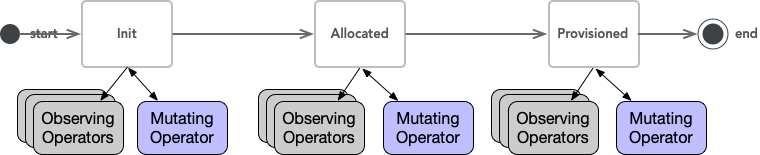
Objects are any networking object, that the management plane derives their life-cycle. When it's first created an object becomes in Init state. Multiple operators work together - in a distributed way - to evolve an object state to a Provisioned state. Between the Init and the Provisioned state, an Operator may transition the object's state to other intermediate states that are specific to the data-plane requirements. Once the object is Provisioned it implies that the data-plane is ready to function given that object symantics.
We refer to this process as the Object-pipeline, which is illustrated in the following diagram of a Generic Object Pipeline. We will explain several example of the application of this approach to develop Mizar's workflows.
Operators program the data-plane through direct RPC interfaces exposed by Transitd (a daemon-set running in each worker host). These RPC interface allows the management plane to follow the well-known design pattern of having less number of management-plane clients call large number of servers to prevent failures to cascade between components. Also having "One" daemon-set exposes multiple extensible RPC interfaces minimizes the number of agents on the hosts, improves deployment story, and reduces the chances of cycle-stealing from actual workload on the host.
We split Objects and Operators into two main categories: Generic, and DataPlane specific. The Generic objects are necessary for any cloud-networking solutions such as: VPC (or Network in Neutron terminology), Network (or Subnet in Neutron), Endpoint (or Port in Neutron), And Droplet which specifies a host (Or a Worker node in Kubernetes). The other category of objects are those that are data-plane specific; For Mizar these are Bouncers and Dividers Objects. Each Object's must specify a "status" field that indicates the status of the object in the pipeline. Two statuses are necessary: Init, and Provisioned. In the PoC, the Management plane has four generic objects: Droplet, VPC, Network, and Endpoint. Each Object is specified using Custom Resource Definitions (CRDs).
Each Operator is responsible for maintaining the data of one and only one object (Stateful Object). We call this a Stateful Object from the operator perspective, since the Operator maintains its data. It is mandatory that an Operator updates the data for its Object when it is in the Provisioned state and optional in any other state. Operators may also mutate the state of objects other than its Stateful Object, but never store these objects data. We call these Objects Mutable objects from an Operator perspective. The Objects types with respects to Operators will become clear as we detail Mizar's workflow.
The specification of an Operator's Stateful Object, Mutable Object, and Mutating Actions are what defines the management plane workflow.
Inter-Operators Communications
Operators communicate with each other to evolve the object's state. When an operator mutates the state of the object it invokes the next operator(s) in the object pipeline. The invocation is done through a callback mechanism. According to the deployment and specific implementation the callback is translated into one of multiple modes. In all of these modes, the operator developer only focuses on the workflow through calling the callback function without worrying about the details of the communication implementation.
- Through the API Server(s): In this mode, an operator only changes the object state and updates the object through the API Server. As one operator makes the callback to invoke the next step of the object pipeline, the only changes the object state and update the object rhough the API server. As the next Operator in the pipeline handles the object in the new state, communication happens implicitly. The drawback of this approach is the load on the API server, and the latency involved to evolve the object's pipeline. The advantage is that the object state is always tracked through the system.
- Direct Service Communication: In this mode, operators exposes a service interface through RPC or any other mechanism, and the callback effectively calls the RPC on the other operator. The calling operators must handle failure scenarios in such case. The drawback of this approach is the complexity of handling failure scenarios. Also, as the intermediate states of the objects are not updates to the API server, it becomes harder to troubleshoot problems in the object-pipeline. This approach may have latency advantage, especially if the API server communication is a bottlneck. However, if the API server and kubernetes storage scales horizontally latency of the this approach and the second approach may be comparable. In that case, this approach only adds implementation complexities that are hard to diagnose.
- Simple Function Calls: In this mode, all operators are deployed into a single (horizontally scalable) operator. The functional implementation of the operators is still seperated through call-back interfaces. But the callbacks are implemented as simply function calls. This approach is the simplest to develop, test, and diagnose. It also minimizes the latency since there is no network communication between the operators. Only the initial and final state of the objects must be updated through the API server. All other intermediate states are hidden. The drawback of this approach though is that local object store of the operator may have a huge size. The other drawback is similar to the second mode where the intermediate states of the objects are not avaiable to the API server; hence, it is harder to troubleshoot and track the object state for problem diagnosis.
The drawback of the third approach are of a less impact on the development, performance, and operation. Not to mention simplicity. First, we can solve the local object store size problems by means of sharding through an operator proxy layer (which is a typical design pattern). The proxy layer shards the objects across replicas of the operator hence both reduce overload and local object store size. Second, the other drawback of tracking the object state for troubleshooting becomes less of a concern in the simple function calls mode because state transitions is within the same process with unified logging, and metering.
Local object store (LMDB) and Resumable Workflow
Each Operator will have a local K/V store implemented with LMDB. Each Operator stores its Stateful Object in this store when it reaches the state "Provisioned" and deletes it when the object is recycled (deleted). The objects are stored in their Provisioned state, there is no need to develop a complicated cache synchronization mechanism as the object is cached into an final (immutable) state.
Given the operator being a StatefulSet, the store persists in the volume. When the operator is replaced it resumes the workflow by serving stalled objects in the API server (in Init or recorded intermediate state) utilizing the data of the provisioned objects in the local store. In this regard, the local store serves two purposes:
- It caches the final object's data into its operator, hence reduces the need to frequently get the object through the API server.
- The store accelerates the starting time of the operators after a failure.
Extension to an external store
The current implementation uses a simple hash map to cache the local state. However, the implementation is extensible if we find a need to interface with an external store other than that provided by Kubernetes.
Horizontal Scaling
Operators shall be deployed as stateful replica set, where Kubernetes auto-scales the number of operators according to their resource metrics or custom metrics. To ensure that the horizontal scaling is effective, the operator proxy layer partitions the requests to be handled by each individual operator. The partitioning is by means of typical hash ring, where the key is the VPC. Partitioning by the VPC ensures data locality of operators that relies on the function calls as inter-operator communications.
The proxy layer itself is left unimplemented, we shall reuse the partitioning schemes proposed in the Arktos project. It's left in the design diagram for completeness, or for future standalone implementations.